IBM SPSS Modeler, komerční klasika
- David Chudán

- 17. 2. 2023
- Minut čtení: 6
Část 1 - klasifikační úloha na datech Titanic
Modeler je software pro data mining a textovou analytiku s dlouhou historií a to až do devadesátých let minulého století (konkrétně rok 1994). Původně se tento produkt jmenoval Clementine a jeho tvůrcem byla společnost Integral Solutions Limited. Tuto firmu koupila společnost SPSS. Nejprve došlo pouze k mírnému přejmenování na SPSS Clementine, později byl produkt přejmenován na PASW Modeler. V roce 2009 společnost SPSS koupilo IBM a software byl přejmenován do dnešní podoby, IBM SPSS Modeler. V současné době je k dispozici verze programu 18.4 vydaná v červnu 2022.
IBM nabízí software ve verzi Professional, což je již téměř historický způsob jednorázové koupě software, dále verzi Gold, která navíc nabízí analytický nástroj IBM Watson Studio Desktop a cloudovou službu IBM Watson Machine Learning. Poslední možností je software jako služba, tedy předplatné probíhající v měsíčních platbách. Kromě toho je software zdarma k dispozici pro univerzity.
Základní princip práce s nástrojem je podobný jako v RapidMineru, který jsem popisoval v předchozím příspěvku. Odlišná je ovšem i základní terminologie. Základním stavebním prvkem zde jsou uzly (nodes), které se spojují do streamu, který je ekvivalentem procesu v RapidMineru, má nicméně některé odlišnosti. Dále v Modeleru figurují projekty a modely. Pojďme si tyto pojmy trochu objasnit.
Stream - reprezentuje tok dat skrze jednotlivé operace (uzly). Čili propojení jednotlivých uzlů formuje stream.
Model - pokud stream obsahuje modelovací uzel (tj. uzel z karty Modelování), je při spuštění streamu vytvořen modelový uzel. Modelový uzel je kontejner modelu, tj. souboru pravidel, vzorců nebo rovnic, který následně umožňuje například vyhodnocení modelu nebo jeho použití pro nová data.
Project - větší množství souborů, které souvisí s data miningovou úlohou. Projekty zahrnují datové toky, grafy, vygenerované modely, sestavy a cokoli dalšího, co jste vytvořili v Modeleru.
K Modeleru je k dispozici rozsáhlá dokumentace týkající se nejen samotného nástroje, ale například popisu jednotlivých algoritmů (na to se ovšem bez Matfyzu raději ani nedívejte :-) ), nebo metodiky CRISP-DM.
Hlavní obrazovku Modeleru ukazuje Obrázek 1.

V horní části obrazovky je k dispozici klasické rozbalovací menu s možnostmi editování, vložení, nástrojů, přičemž některé hodně používané možnosti jsou k dispozici prostřednictvím ikon hned pod tímto menu. Ve spodní části jsou umístěny všechny uzly, rozdělené do kategorií jako zdroje (sources), práce s daty na úrovni záznamů (Record Ops), práci s daty na úrovni sloupců (Field Ops) atd. V pravé části vidíme jednak seznam streamů s možností přepnutí na výstupy z projektu, dále na modely vytvořené v daném streamu. Poslední část, CRISP-DM, obsahuje fáze metodiky CRISP-DM, což je standardní postup pro řešení data miningových projektů, který se skládá z fází, které jsou vidět na obrázku. Sem je možné například vkládat soubory obsahující popis dat, nebo jakékoliv materiály, které s danou analýzou souvisejí.
Analýza dat Titanic
Analýzu začneme nahráním dat, což uděláme prostřednictvím uzlu Var. file, který slouží k přečtení dat z textového souboru s daty oddělenými pomocí oddělovačů. Oproti RapidMineru jde Modeler cestou méně použitých uzlů, protože celá řada operací, která se v RapidMineru každá řeší pomocí vlastního operátoru, lze zde vyřešit s využitím jednoho. Hned v uzlu Var.File lze nastavit datové typy, vyfiltrovat atributy, které do analýzy vstoupí a nastavit typy z hlediska analýzy, čili nastavit cílový atribut. Terminologie se s RapidMinerem neshoduje v podstatě vůbec, takže nastavení cílového atributu se zde dělá pomocí Role => Target. Abychom se mohli na data podívat, je třeba použít některý z uzlů, které nachází v kategorii Output. Základní vizualizační možnost je prostá tabulka (uzel Table). Další odlišností oproti RapidMineru je to, že můžeme pouštět libovolnou část streamu. Stream se tedy může větvit a ničemu nevadí, pokud některé uzly nejsou propojené. Můžeme spustit libovolnou část celého streamu. Ne všechny uzly je ovšem možné spustit, abychom dostali nějaký výstup, musí se jednat o uzly z kategorie Output, Graphs, nebo Export.
Prvním úkonem v naší práci s daty Titanic je odfiltrování nepotřebných sloupců. To provedeme v již zmíněném Var.File v záložce Filter, kde zaškrtneme všechny nepotřebné atributy, tedy PassengerID, Ticket a Cabin. V záložce Types následně nastavíme roli atributu Survived na Target.
Nyní přejdeme do fáze exploratory data analysis. Modeler nabízí jednak grafy, a jednak textové výstupy v kategorii Output. V grafech jsou k dispozici standardní věci jako histogramy, bodové diagramy, až po zajímavé možnosti vizualizace, jako je interaktivní E-plot, který umožňuje provádět různé změny na již hotovém grafu. Na Obrázku 2 vidíme vztah věku pasažérů a atributu Parch, tedy počtu rodičů / dětí jakožto spolucestujících.

V textových možnostech výstupu je k dispozici klasická tabulka pro zobrazení dat (Table), matici zkoumající vztahy mezi atributy (zde je možné například zjistit agregační funkce pro kombinaci atributů, čili můžeme zde zjistit průměrný věk pasažérů podle pohlaví a třídy, kterou cestovali - viz Obr. 3)

Dále je k dispozici uzel Data Audit, přinášející podrobné informace o datové kvalitě, tedy informace o počtu chybějících hodnot, o extrémních hodnotách, prázdných polích, a dále přináší celou řadu statistik, jako korelace mezi atributy, rozptyl, směrodatnou odchylku a další.
Nyní přejdeme na vlastní přípravu dat. První krok přípravy dat, vyfiltrování atributů, jsme vyřešili už ve fázi importu dat. Dalším krokem je extrakce titulu ze jména. K tomu využijeme uzel Derive, který nabízí opravdu široké možnosti úprav sloupců s využitím editoru výrazu (expression builder). Jsou zde k dispozici porovnávací funkce, logické, matematické a pochopitelně funkce pro práci s textovými řetězci. Celkový počet funkcí se blíží počtu funkcím v Excelu. Konkrétně pro úlohu extrakce titulu použijeme následující výraz: textsplit(Name,1,"."), který rozdělí textový řetězec podle znaku tečky na část křestního jména, následně příjmení, a poté tento uzel aplikujeme ještě jednou s následujícím výrazem: textsplit(Title_part,2," "). Title_part je pomocný sloupec, který byl vytvořen při první aplikaci extrakce titulu. Jako název tohoto odvozeného slupce dáme Title.
Následně přidáme uzel Filter, pomocí kterého odstraníme původní atributy Name a vytvořený Title_part. Nyní máme atribut Title, který obsahuje poměrně hodně různých extrahovaných hodnot titulu (jako například Master, Rev, Col a další). Kromě základních oslovení Mr, Mrs a Miss jsou ostatní tituly mále četné. Proto všechny tyto hodnoty sloučíme do jedné kategorie pojmenované Other. Toho docílíme prostřednictvím uzlu Reclassify, kde použijeme možnost For inspecified values use: Default value "Other". Do tabulky je ale potřeba zadat i neměnné hodnoty atributu, již zmíněné Miss, Mr a Mrs (viz Obrázek 4).
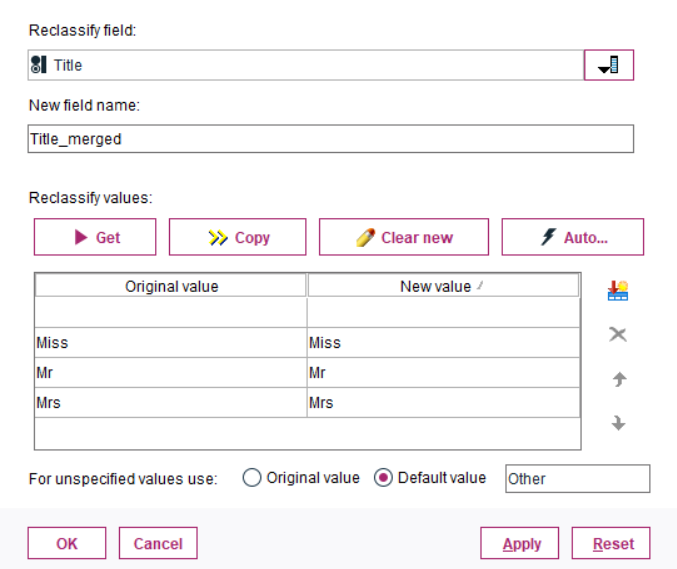
Následně je třeba vyřešit chybějící hodnoty, které se v datech nacházejí u numerického atributu Age a u kategoriálního atributu Embarked. Chybějící hodnoty se v Modeleru řeší poněkud netypicky a to tak, že je třeba použít uzel Data Audit. Zde se přepneme na záložku Quality, ve které vidíme informace o počtu chybějících hodnot. Tyto chybějící hodnoty potom nadefinujeme pomocí sloupce Impute Missing, kde zvolíme null values a následně zvolíme ve sloupci Method jakým způsobem chybějící hodnoty ošetříme. Zůstaneme u té nejjednodušší varianty a u atributu Age (viz. Obr. 5) nahradíme chybějící hodnoty průměrem, u Embarked potom modusem.

Samotný uzel Data audit nám ovšem chybějící hodnoty neodstraní. Je potřeba kliknout na tlačítko Generate (na výše uvedeném ovrázku je zvýrazněno červenou barvou), které umožní vygenerování tzv. Missing Values SuperNode.
Takto vygenerovanou supernode následně přidáme do našeho streamu a tím se chybějících hodnot zbavíme.
Následujícím krokem je diskretizace atributů Age a Fare. Oba atributy rozdělíme do pěti ekvifrekvenčních kategorií, tedy stějně četných intervalů o délce 5. Data se tak rozdělí do kvintilů (Obrázek 6).

Nyní zbývá vyfiltrovat původní atributy pomocí uzlu Filter a následně zpracovat atributy SibSp a Parch. Z těchto atributů vytvoříme nový binární atribut pojmenovaný IsAlone, který identifiguje cestující, kteří cestovali sami (hodnota 1), a cestující, kteří cestovali s někým (hodnota 0). Atribut vytvoříme pomocí uzlu Derive s využitím následující podmínky (Obrázek 7):

Nyní pomocí uzlu Filter nastavíme roli atributu Survived jako Target (tj nastavujeme tento atribut jako cílový pro klasifikační úlohu) a můžeme přistoupit k výběru vlastních supervised modelů pro klasifikaci. Vybereme logistickou regresi, rozhodovací strom (C5.0), random forest a neuronovou síť. Všechny tyto modely připojíme za uzel Filter. Celý stream spustíme, přičemž se nám vygenerují uzly obsahující vlastní modely. Tyto uzly jsou k dispozici na pravé straně pod Models. Všechny takto vytvořené modely připojíme za uzel Filter (přičemž původní uzly, které generují vlastní modely můžeme smazat, aby se úloha po dalším spuštění znovu nepřepočítávala). Za každý model dodáme uzly Analýza a Matrix, které nám umožní model vyhodnotit pomocí matice záměn. Celý proces je zobrazen na Obrázku 8.

Po spuštění tohoto celého streamu se otevře celkem 11 různých oken (která odpovídají všem tabulkám a uzlům Analýza) s informacemi jednak o datasetu, a také o proběhlé analýze prostřednictvím matic záměn a analýz pro každý použitý klasifikátor (tedy 4x2 oken). Kromě toho můžeme prozkoumat každý vytvořený model (po kliknutí na ikonu modelu reprezentovanou diamantem). Je tak možné například prozkoumat vytvořený rozhodovací strom, viz Obrázek 9.

Podíváme-li se na porovnání jednotlivých modelů, tak nejlépe si stojí decision forest se správností 86,87 %, následovaný jednoduchým rozhodovacím stromem založeným na algoritmu C5.0 se správností 84,85 %. Neuronová síť a logistická regrese si stojí hůře, což není překvapivé, protože data jsou především kategoriální.
Stejně jako v případě článku o RapidMineru se budu věnovat metodám unsupervised learningu v odděleném článku.


Komentáře